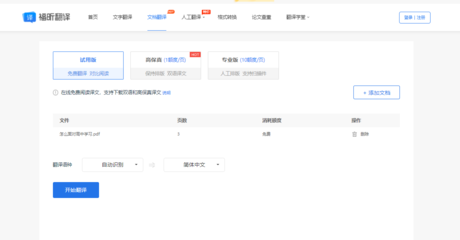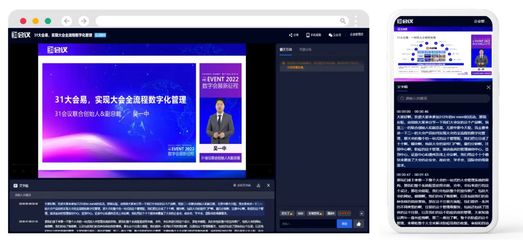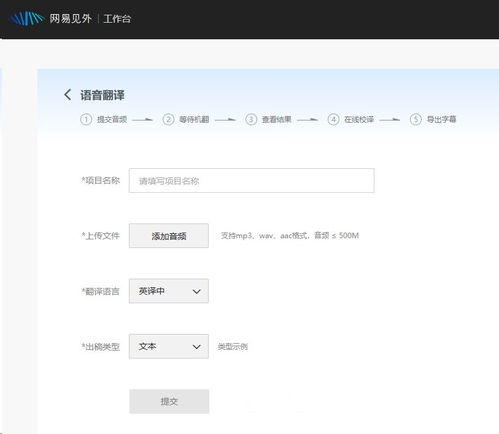
音頻翻譯是現代軟件開發中越來越重要的技術領域,它結合了語音識別、機器翻譯和語音合成三大核心技術。無論是跨國會議記錄、外語學習輔助,還是多媒體內容本地化,音頻翻譯技術都在發揮著關鍵作用。
工作原理:
音頻翻譯首先通過語音識別(ASR)技術將音頻轉換為文本,這個過程需要處理不同口音、語速和背景噪音的挑戰。機器翻譯引擎對識別出的文本進行跨語言轉換。通過語音合成(TTS)技術將翻譯結果重新轉換為目標語言的音頻輸出。
技術實現要點:
- 音頻預處理:降噪、語音增強、音頻分割
- 語音識別:基于深度學習的端到端模型
- 文本處理:標點恢復、文本標準化
- 機器翻譯:神經網絡翻譯模型
- 語音合成:波形生成與語音自然度優化
開發實踐建議:
- 選擇成熟的語音識別SDK(如Google Speech-to-Text、Azure Speech)
- 集成可靠的翻譯API(如Google Translate、DeepL)
- 考慮實時性與準確性的平衡
- 優化多語言支持與方言處理
- 確保數據隱私與安全
應用場景:
? 實時會議翻譯系統
? 播客與視頻內容本地化
? 語言學習應用程序
? 客服語音機器人
? 多媒體檔案數字化
未來發展趨勢包括端到端模型的優化、低資源語言的覆蓋提升,以及個性化語音風格的保留。隨著AI技術的進步,音頻翻譯的準確性和自然度將持續提升,為跨語言交流帶來更多便利。